컴퓨터 언어는 어떻게 해석될까?
2023년 7월 16일컴퓨터는 컴퓨터 언어를 어떻게 처리하고 해석하는 걸까요? C 언어는 소스 코드를 작성하고 컴파일 후 나온 결과물을 가지고 실행합니다. Python 언어는 소스 코드를 작성하고 터미널을 통해 python [FILE].py 명령어로 코드를 실행할 수 있습니다. 개발자들은 컴파일러와 인터프리터의 도움으로 컴퓨터 언어 문법만 익힌다면 작성한 코드의 결과물을 볼 수 있습니다. 어떻게 컴파일러와 인터프리터가 컴퓨터 언어를 ‘해석’하는지 궁금하시지 않았나요? 이번 글을 통해 이 모든 것을 설명하기 힘들겠지만 간략하게 전체적인 컴파일러, 인터프리터 동작 방식을 Crafting Interpreters의 책을 기준으로 정리해보려 합니다.
컴퓨터 언어를 쓰다보면 한 번씩 이런 생각이 들었습니다. 어떻게 int, for와 같은 식별자를 구분하는거지? 어떻게 변수 a를 기억하는거지? 어떻게 클래스의 인스턴스를 생성하는거지?
컴파일러와 인터프리터가 컴퓨터 언어를 해석하기 위해 첫 번째로 하는 일은 scanning(lexing, lexical analysis, 어휘 분석, 이하 스캐닝)입니다. 스캐닝 과정에서 소스 코드의 문자열(strings)이 어떤 종류인지 분석하는 작업을 합니다. int는 정수 타입을 나타내는 단어이고 123은 숫자를 나타내는 단어이고 for는 반복문이 시작되는 단어임을 분석합니다. 이런 의미있는 단어들을 token이라고 합니다.
Token은 type, lexeme, literal으로 이루어져있습니다. Lexeme은 token의 문자 그 자체를 의미합니다. Literal는 token의 문자, 숫자, boolean, null 같은 직접적인 값을 의미합니다. 아래의 예시로 token, lexeme, literal 차이를 알아봅시다.
TEXTvar a = 1; // Token: var // ├─ Type: VAR // ├─ Lexeme: var // └─ Literal: null // Token: a // ├─ Type: IDENTIFIER // ├─ Lexeme: a // └─ Literal: null // Token: = // ├─ Type: EQUAL // ├─ Lexeme: = // └─ Literal: null // Token: 1 // ├─ Type: NUMBER // ├─ Lexeme: 1 // └─ Literal: 1 // Token: ; // ├─ Type: SEMICOLON // ├─ Lexeme: ; // └─ Literal: null
스캐닝 과정이 끝나면 다음으로 parser(syntax analysis, 구문 분석, 이하 파서) 과정을 거칩니다. 파서 과정에서는 문법 규칙에 따라 abstract syntax tree(추상 구문 트리, 이하 AST)를 만듭니다. 스캐닝의 결과로 나온 token들은 정규 언어(regular language)의 형태를 따릅니다. 정규 언어는 반복적인 패턴을 만드는데 적합하지만 구문 분석하는데 어려움이 있습니다. 정규 언어는 각각의 token들이 독립적으로 존재하기에 주위의 문맥을 고려하지 않아 다양한 표현법을 만들기 불편합니다. 이런 문제를 해결하기 위해 정규 언어보다 상위 개념인 Context-free Language(문맥 자유 언어, 이하 CFL)를 사용합니다. Context-free Grammar(문맥 자유 문법, 이하 CFG)으로 만들어진 CFL는 정규 언어보다 자유로운 구조를 표현할 수 있습니다. 만약 세미콜론으로 끝나는 언어 문법을 만들고 싶다면 아래와 같이 CFG를 만들 수 있습니다.
정규 언어를 통해 만든 언어를 정규식(Regular Expression)이라고 합니다.
TEXTexpression → literal | unary | binary | grouping ; literal → NUMBER | STRING | "true" | "false" | "nil" ; grouping → "(" expression ")" ; unary → ( "-" | "!" ) expression ; binary → expression operator expression ; operator → "==" | "!=" | "<" | "<=" | ">" | ">=" | "+" | "-" | "*" | "/" ;
CFG를 표현하기 위해 BNF 표기법(→ | 와 같은)을 사용합니다. BNF에서 문법적으로 최종적인 단계 즉, 더 이상 분해할 수 없는 요소를 terminal(터미널)이라고 합니다. 반면에 문법 규칙에 따라 계속 파생(derivation)될 수 있는 요소를 nonterminal(비터미널)이라고 합니다. “Hello”, 123과 같은 요소를 terminal이라 하고 expression, literal, grouping 같은 요소를 nonterminal이라고 합니다. Expression(식)은 산술식, 논리식, 변수 할당식, 함수 호출식과 같이 계산될 수 있는 식을 말합니다.
TEXT"Hello"; // literal !1; // unary "123" != nil; // binary (123); // grouping
var a = 1; 코드를 위에서 정의한 문법을 적용한 파서에 넣으면 다음의 AST를 얻을 수 있습니다.
TEXT// Exmaple code var a = 1; // AST VariableDeclaration ├── Identifier: a └── Literal: 1
AST 구조는 정의한 문법에 따라 달라질 수 있습니다. AST는 nonterminal이 파생되어 terminal이 될 때까지 재귀를 통해 생성됩니다(expression는 grouping, unary, binary로 파생될 수 있습니다). 위 문법으로 코드가 어떤 ‘의미’인지는 파악할 수 있지만 그 이상은 확인할 수 없습니다. 문법을 확장하여 코드의 ‘상태’를 알 수 있도록 해봅시다.
Expression의 값을 기억하기 위해서는 상태(state)를 저장하는 무언가가 있어야합니다. 상태를 기억하기 위해 statement(문)을 사용합니다. Expression는 값 표현을 담당하고 statement는 변수 할당문, 제어문, 반복문, 출력문 표현을 담당합니다. Statement는 하나 이상의 expression을 갖으며 expression와 달리 side effect가 존재합니다.
TEXTstatement → exprStmt | forStmt | ifStmt | printStmt | returnStmt | whileStmt | block ; exprStmt → expression ";" ; forStmt → "for" "(" ( varDecl | exprStmt | ";" ) expression? ";" expression? ")" statement ; ifStmt → "if" "(" expression ")" statement ( "else" statement )? ; printStmt → "print" expression ";" ; returnStmt → "return" expression? ";" ; whileStmt → "while" "(" expression ")" statement ; block → "{" declaration* "}" ; ** 변수, 함수, 클래스 선언은 statement nonterminal에 정의하지 않고 ** declartion nonterminal로 따로 정의하기도 합니다. declaration → varDecl varDecl → "var" IDENTIFIER ( "=" expression )? ";" ;
TEXT// Expression 1; a; 1 + 2; // Statement a = 2; a = 1 + 2; while (a < 10) {} if (a == 1) return a;
위 문법을 보면 expression는 statement에 속한다는 것을 알 수 있습니다. Expression는 값을 생성하거나 계산하는데 집중하고 statement는 값에 대해 신경 쓰지 않고 expression을 출력하거나 다른 동작(ex. 흐름 제어, 반복 제어, return문, print문)에 대한 처리를 합니다. Expression과 statement로 역할을 나눔으로써 디버깅 및 유지보수를 하거나 코드 재사용에 유용합니다.
Statement도 스캐닝과 파서에 의해 해석되고 AST를 반환합니다.
TEXTWhileStatement ├── Identifier: condition │ └── BinaryExpression │ └── Left: a │ └── Operator: < │ └── Right: 10 └── Identifier: body
스캐닝과 파서에서 statement를 해석했지만 아직 부족한 정보가 있습니다. 파서는 구문 분석만 할 뿐 ‘변수에 대한 정보’를 알 수 없습니다. 변수가 어디에 선언되었는지, 어떠한 값을 가졌는지 알기 위해 정적 분석(static analysis)의 의미 분석(semantic analysis) 과정이 필요합니다. 선언한 변수 a가 전역 변수인지, 지역 변수인지, 유효한 변수인지에 대한 정보가 있어야 사용자가 의도한 대로 동작할 수 있습니다. 만약 이런 정보가 없다면 다음과 같은 결과를 얻을 수 있습니다.
Cint a = 1; { int a = 2; printf("output: %d", a); } // output: 1
현대 프로그래밍 관점에서 출력되어야 할 a의 값은 printf 이전에 a를 정의한 값인 2가 출력되어야 합니다. 변수 a에 대한 정보를 알기 위해 hash table 형태의 locals와 environment 변수를 참고하여 파악합니다.
의미 분석하는 도중 variable(ex. print a의 a), assignment(ex. a = 200) expression을 만나면 locals 변수에 expression 정보와 현재의 scope가 global scope으로부터 얼마나 떨어져 있는지에 대한 depth를 저장합니다. 그 다음 인터프리터와 컴파일러가 statement를 해석할 때 locals와 environment 변수를 참고하여 알맞은 변수를 찾습니다.
예를 들어, 사용자가 print a; 라는 statement를 작성했다면 다음과 같은 과정을 거칩니다.
- 어휘 분석과 구문 분석을 마치고 의미 분석 과정으로 들어간다
- variable, assignment와 같은 expression을 만나면 해당 expression 정보와 depth를
locals변수에 저장한다
- variable, assignment와 같은 expression을 만나면 해당 expression 정보와 depth를
- 의미 분석 후 값을 출력한다
VisitPrintStmt함수을 호출한다(print)VisitVariableExpr함수를 호출한다(a)VisitPrintStmt→evalute→VisitVariableExpr
lookUpVariable함수를 호출한다locals변수를 참고하여aexpression이 있는지 확인한다locals변수에aexpression이 있으면environment변수에서 해당 정보를 찾아서 반환한다locals변수에aexpression이 없으면globals변수에 해당 정보를 찾아서 반환한다
VisitPrintStmt함수는lookUpVariable로부터 반환된 값을 출력한다
GOtype Environment struct {
values map[string]any
enclosing *Environment
}
type Interpreter struct {
globals *env.Environment
environment *env.Environment
locals map[ast.Expr]int
}
func (i *Interpreter) VisitPrintStmt(stmt *ast.Print) any {
value := i.evaluate(stmt.Expression)
fmt.Println(stringify(value))
return nil
}
func (i *Interpreter) VisitVariableExpr(expr *ast.Variable) any {
return i.lookUpVariable(expr.Name, expr)
}
func (i *Interpreter) lookUpVariable(name token.Token, expr ast.Expr) any {
if distance, ok := i.locals[expr]; ok {
return i.environment.GetAt(distance, name.Lexeme)
}
return i.globals.Get(name)
}
TEXT// Example code var a = 1; var b = 2; var c = 3; { var a = 10; var b = 20; { var a = 100; print a; print b; print c; } print a; } print a; print b; // Output 100, 20, 3, 10, 1, 2 // AST Interpreter ├── globals │ └── values │ └── a = 1 │ └── b = 2 │ └── c = 3 ├── environment │ ├── values // 가장 안 쪽의(depth 0) env │ │ └── a = 100 │ └── enclosing │ ├── values // 한 번 scope 들어간(depth 1) env │ │ └── a = 10 │ │ └── b = 20 │ └── enclosing │ └── values // 가장 바깥 쪽의(global, depth 2) env │ └── a = 1 │ └── b = 2 │ └── c = 2 └── locals └── values └── a = 0 // 첫 번째 print a의 a는 depth가 0 └── b = 1 // 첫 번째 print b의 b는 depth가 1 └── c = 2 // 첫 번째 print c의 c는 depth가 2 └── a = 0 // 두 번째 print a의 a는 depth가 0
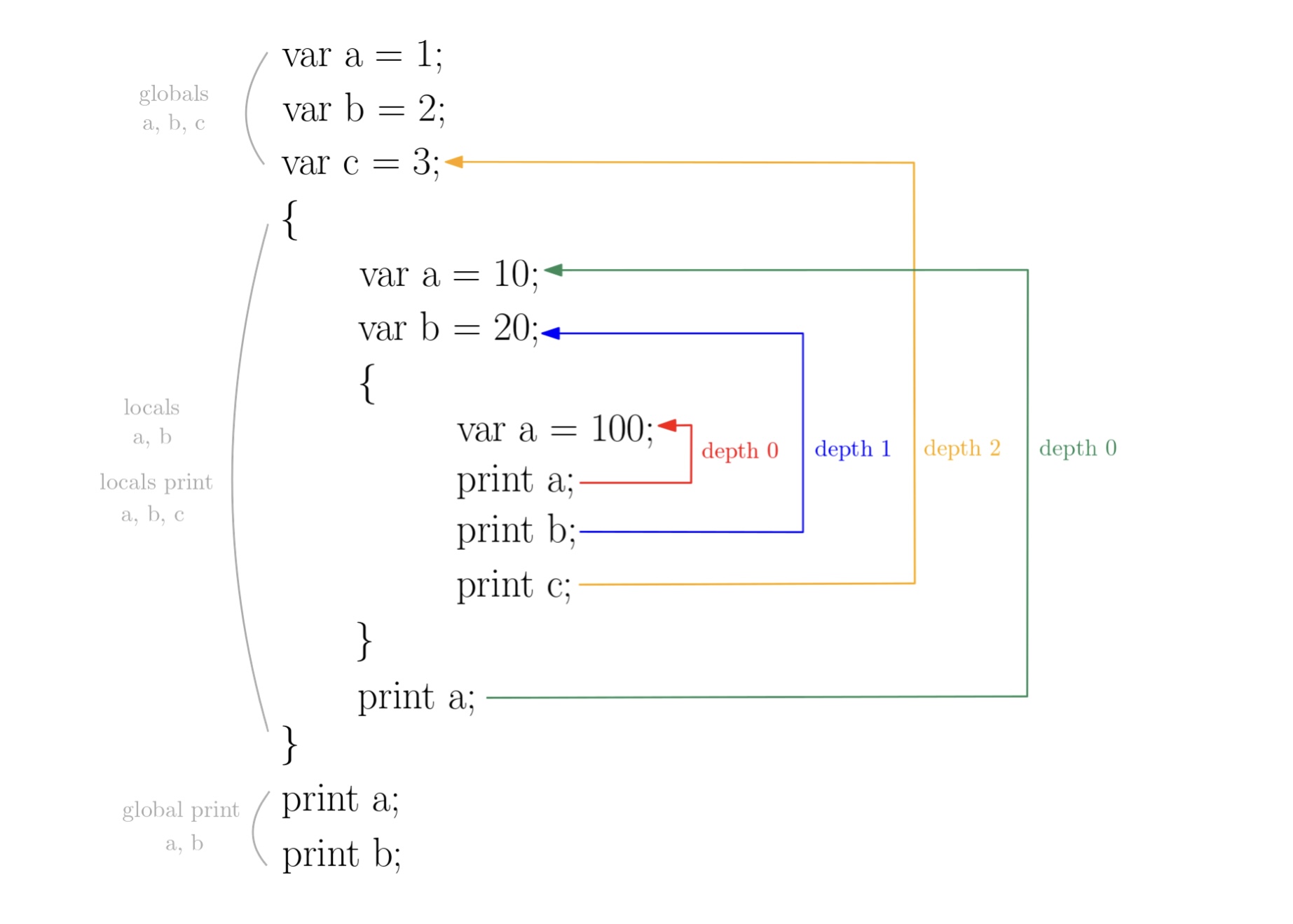
의미 분석까지 완료하였다면 컴퓨터 언어를 해석할 수 있는 간단한 컴파일러, 인터프리터를 만들 수 있습니다. 함수, 클래스와 같이 더 많은 기능을 지원하고 싶다면 추가적으로 문법을 정의하고 이에 맞는 AST가 생성되도록 스캐닝, 파서, 인터프리터 혹은 컴파일러를 수정하면 됩니다.
앞서 소개한 방법 이외에도 컴파일러와 인터프리터는 많은 일들을 합니다. 정적 분석 과정에서는 의미 분석뿐만 아니라 강타입 언어일 경우 타입을 확인하여 type error를 확인합니다. 정적 분석 후에는 constant folding, loop unrolling, dead code elimination과 같은 최적화 과정을 진행합니다. 컴파일러가 만든 bytecode를 어느 플랫폼에서도 사용할 수 있는 가상 머신(VM)에 넣어 컴퓨터 언어를 실행할 수 있습니다. GC를 통해 메모리 관리도 할 수 있습니다.
컴퓨터 언어는 컴퓨터 역사와 함께하면서 다양한 언어, 철학, 방식이 있습니다. 컴퓨터 언어 구조를 이해하기는 결코 쉬운 일이 아니지만 조금씩 공부하다 보면 분명 다양한 컴퓨터 언어 세계에 대해 이해할 수 있을 겁니다. 컴퓨터 언어, 컴파일러, 인터프리터에 대한 이해를 원하는 여러분에게 Crafting Interpreters 책을 추천해 드립니다.