CRDT, 실시간으로 데이터 일관성을 유지하는 법
2024년 2월 27일Notion, Google Docs, Figma 등의 프로그램은 두 명 이상의 사용자가 실시간으로 데이터를 수정할 수 있습니다. Jetbrains의 Code With Me나 Visual Studio Code의 Live Share 도구 덕분에 편하게 페어 프로그래밍하며 개발자들의 호흡을 맞출 수도 있습니다. 여러 사람이 한 문서를 바라보고 실시간으로 편집하는 건 효율적이며 생산적입니다. 하지만 가만 생각해 보면 신기합니다. 여러 명이 같은 문서를 수정하는데 어떻게 데이터 꼬임 없이 문서를 작성할 수 있는 걸까요? 사용자 A와 사용자 B가 동시에 같은 위치에 문자를 입력한다면 이를 어떻게 처리해야 할까요? 사용자 A가 입력한 문자를 넣어야 할까요? 사용자 B가 입력한 문자를 넣어야 할까요? 그것도 아니라면 중복이 발생했으니 사용자 A, B 입력한 문자를 모두 버려야 할까요?
실시간 협업 도구는 동시다발적인 입력을 처리해야 하기도 하지만 네트워크 유무(온/오프라인), 네트워크 지연과 같은 문제 또한 고려해야 합니다. 이러한 데이터 일관성을 유지하기 위해 나온 잘 알려진 기술로는 OT(Operational Transformation)와 CRDT(Conflict-free Replicated Data Type)가 있습니다. 이 중 CRDT 기술을 중점으로 어떻게 실시간 협업 환경에서 데이터 꼬임과 유실 없이 처리하는지 알아보도록 하겠습니다.
데이터 일관성(consistency)이란 서로 다른 시스템 혹은 장소에 보관된 데이터가 일치하는지를 말합니다.
CRDT는 Conflict-free Replicated Data Type의 약어로 네트워크 상에서 여러 사용자가 충돌없이 데이터를 받을 수 있도록 설계된 자료구조입니다. 이를 코드로 구체화한다면 다음과 같이 표현할 수 있습니다.
TYPESCRIPTinterface CRDT<T, S> {
value: T;
state: S;
merge(state: S): void;
}
CRDT는 최소 value, state, merge() 세 가지 정보를 가집니다.
value: 일관되게 데이터를 유지해야 하는 값 (ex. RGB 색상 값, 코드 라인 수)state: 데이터 일관성을 유지하기 위한 메타데이터 값 (ex. peer id, timestamp)merge(): local state 값과 다른 사용자로부터 받은 state를 병합하는 함수
또한 CRDT는 아래의 특징을 갖습니다.
- The application can update any replica independently, concurrently and without coordinating with other replicas
- An algorithm (itself part of the data type) automatically resolves any inconsistencies that might occur
- Although replicas may have different state at any particular point in time, they are guaranteed to eventually converge
동시에 데이터가 들어오는 동시성 문제를 해결하기 위해 데이터 충돌 자체를 막는 방법도 있지만, 충돌을 허용하고 추후의 병합 과정에서 데이터 불일치를 해결하는 낙관적(optimistic)인 방식도 있습니다. CRDT는 후자에 적합한 자료구조이며 기본적으로 클라이언트 단에서 병합이 이루어집니다. CRDT는 구현 방식에 따라 2가지 종류로 나뉩니다.
- Operational-based (연산 기반)
- Commutative Replicated Data Type 혹은 CmRDT 라고도 불린다
- 사용자 사이에 수정한 state만 주고받고 병합하여 새로운 state를 만든다
- 교환법칙은 적용되지만 멱등성은 적용될 필요가 없다
- State-based (상태 기반)
- Convergent Replicated Date Type 혹은 CvRDT 라고도 불린다
- 사용자 사이에 모든 state를 주고받고 병합하여 새로운 state를 만든다
- 교환법칙, 결합법칙, 멱등성이 적용된다
교환법칙(Commutativity)
- State는 순서와 상관없이 병합될 수 있다
A + B = B + A
결합법칙(Associativity)
- 세 개 이상의 state가 순서에 상관없이 병합하면 똑같은 state를 가진다
(A + B) + C = A + (B + C)
멱등성(Idempotence)
- 자기 자신의 state를 병합하면 변화가 없다
A + A = A
모든 state를 주고받는 state-based 방식과 달리 수정된 state만 주고받는 operation-based 방식이 효율적으로 보입니다. Operation-based 방식이 네트워크 통신 비용을 줄이는 측면으로 좋지만, 결합법칙이 적용이 안 되기 때문에 데이터 간 관계가 중요합니다. 따라서 데이터를 보내는 순서와 전송 회수에 신경 써야 하므로 state-based 방식보다 구현이 다소 복잡합니다. 저희는 보다 구조를 이해하기 쉬운 state-based 방식을 중심으로 살펴보도록 하겠습니다. State-based 방식에도 G-Counter, PN-Counter, Grow-only Set, LWW Register, Sequence CRDTs 등 많은 state-based 방식의 자료구조가 존재합니다. 그 중 간단하게 구현하기 쉬운 LWW Register에 대해 살펴보겠습니다.
LWW Register는 Last Write Wins Register의 약어로 여러 값 중 마지막으로 들어온 값을 현재의 값으로 덮어쓰는 로직을 적용합니다. LWW Register는 timestamp 값을 가지고 있으며 다른 사용자로부터 받은 timestamp와 자신의 timestamp 값을 비교하여 어떤 값을 state로 업데이트할지 결정합니다. LWW Register의 단어 의미에서 유추할 수 있듯이 가장 최신의 timestamp를 가진 state를 다른 사용자들의 state에 덮어씁니다.
TYPESCRIPTtype RGB = [red: number, green: number, blue: number]
type State = [peer: string, timestamp: number];
class LWWRegister<T> {
value: RGB;
state: State;
merge(state: State, value: RGB) {
const [remotePeer, remoteTimestamp] = state;
const [localPeer, localTimestamp] = this.state;
// 수신 받은 timestamp가 local timestamp보다 오래되면 무시한다
if (localTimestamp > remoteTimestamp) {
return;
}
// Timestamp가 충돌이 날 경우 peer string을 비교하여 state를 업데이트할지 결정한다
if (localTimestamp === remoteTimestamp && localPeer > remotePeer) {
return;
}
// 수신 받은 timestamp가 local timestamp보다 최신인 경우 state와 value를 업데이트한다
this.state = state;
this.value = value;
}
그런데 사용자 간의 timestamp 기준이 불일치하다면 어떻게 되는 걸까요? 실제로 사용자의 하드웨어, OS, 웹 브라우저, 네트워크 지연 등의 문제로 timestamp 동기화가 어렵습니다. 여기서 말하는 timestamp는 2024-02-25 18:03:58와 같이 일반적인 시간이 될 수 있고 이벤트들의 인과관계를 알 수 있는 Lamport timestamp처럼 logical clock이 될 수 있습니다. 정말 간단하게는 이벤트(ex. 사용자의 입력)가 발생할 때마다 단순히 1을 증가시키는 logical clock 형태를 사용할 수 있습니다.
LWW Register에서의 ‘register’는 하드웨어에서 말하는 저장 공간인 register와는 다른 의미를 갖습니다. LWW Register에서 말하는 register는 데이터 일관성을 유지하기 위한 논리적인 데이터 저장 단위를 말합니다.
LWW Register는 timestamp는 고유한 값을 가진다고 가정합니다. 하지만 종종 timestamp 값이 같고 value 값이 다른 상황이 발생할 수 있습니다. 이 같은 충돌을 해결하기 위해 LWW Register는 ‘편향된’ 로직을 적용합니다. 예를 들어 peer 이름값을 비교한다든지, value 값을 비교한다든지 혹은 임의의 우선순위를 정하는 로직을 추가하여 timestmp가 같을 경우를 대비합니다. 위 예시 코드에서는 peer string을 비교하여 충돌을 처리합니다. 하지만 이러한 방법은 특정 데이터에 쏠릴 가능성이 있습니다. 만약 Alice와 Bob이라는 두 peer가 존재하고 timestamp 충돌이 난다면 string comparison으로 Alice의 state가 적용되어 Alice가 작성한 데이터에 치우칠 수 있습니다.
편향된 로직으로 LWW Register는 데이터 순서를 보장하지 않을 수 있습니다. 이러한 특징으로 작은 변경이 큰 변경을 덮어쓸 수 있어서 단점으로 다가오지만 빠르게 데이터 동시성을 해결하여 일관성을 유지할 수 있습니다. 데이터 순서가 중요한 서비스를 고려한다면 LWW Register보다 Sequence CRDT 방식이 적절합니다.
CRDT의 LWW Register에 관해 설명하였습니다. 설명한 내용을 바탕으로 두 명의 사용자(Alice, Bob)가 그림판을 공유하며 그림을 그리는 상황을 예시로 살펴봅시다.
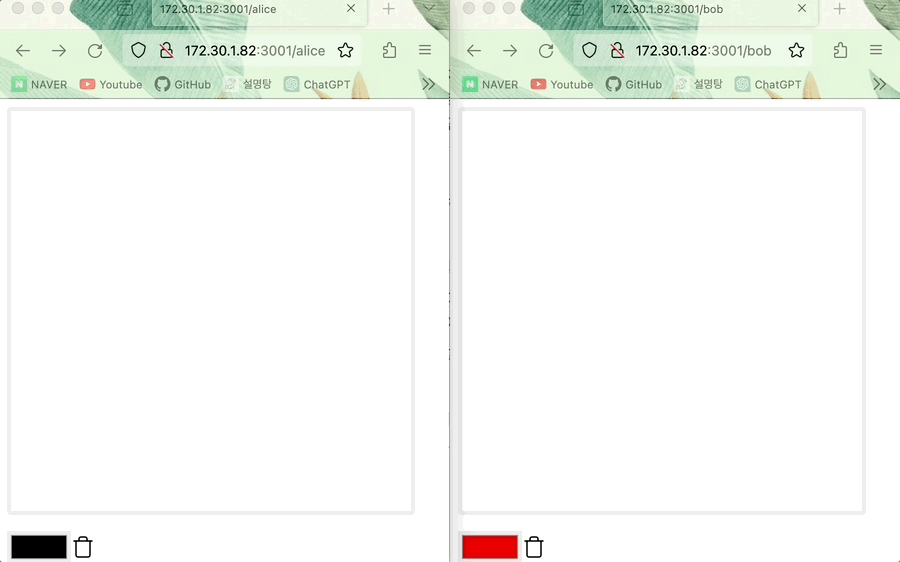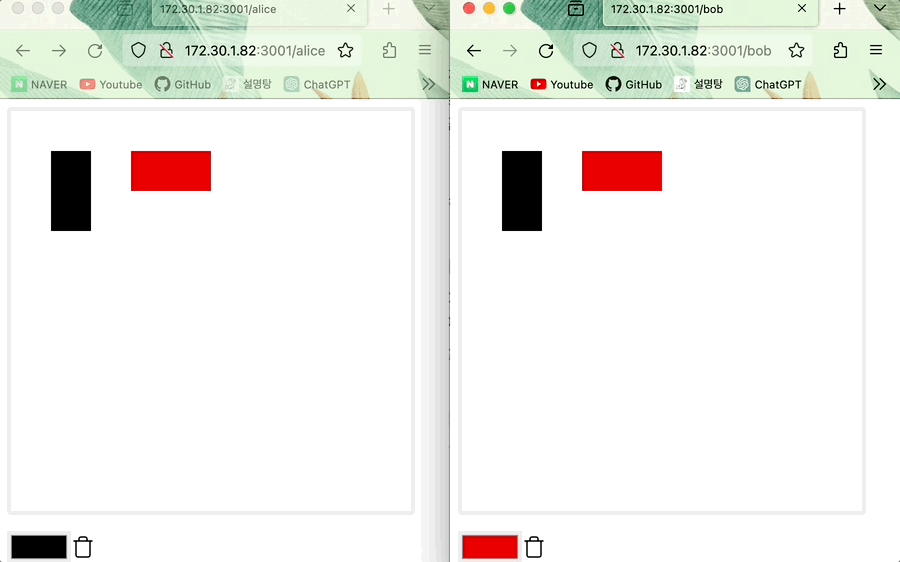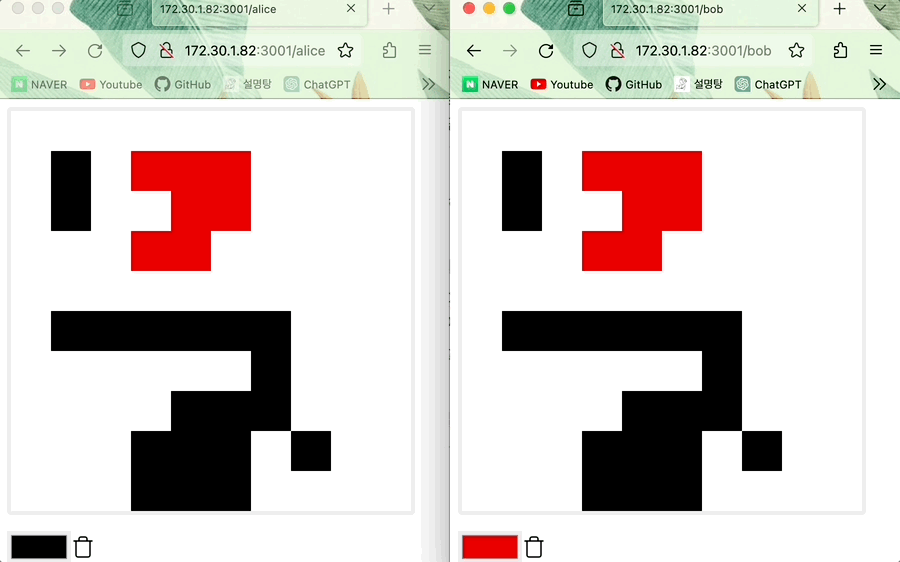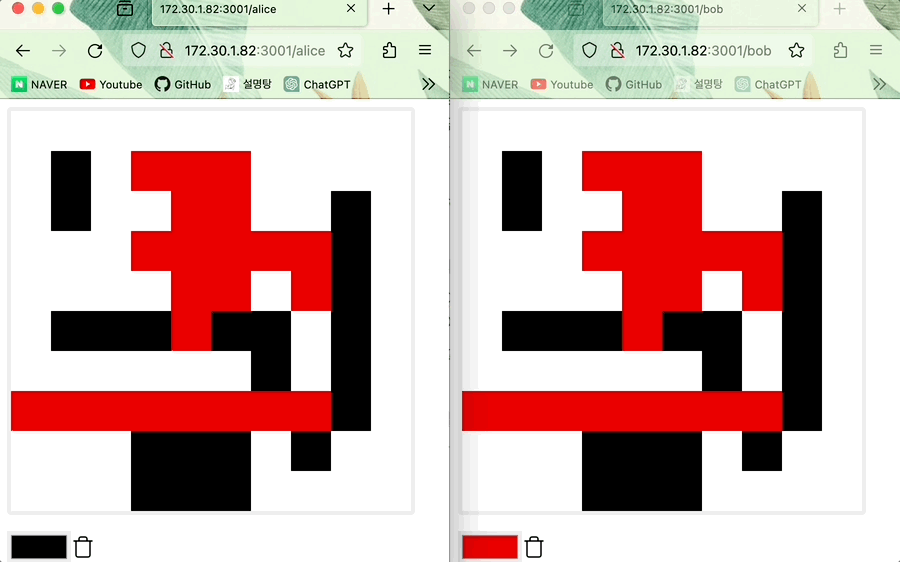
- (온라인) Alice의 그림이 Bob의 캔버스와 동기화되며 그 반대도 동일하다
-
(오프라인) Alice가 그린 그림 위에 Bob이 그 위를 덧그리고 온라인으로 전환한 다음 그림을 그리면 state 업데이트 진행되어 Bob의 그림이 적용된다 (데이터 일관성이 유지된다)
- 최신의 timestamp가 먼저 적용되는 LWW Register이므로 같은 위치에 Alice와 Bob이 그렸다면 뒤에 그린 Bob 그림이 적용됩니다.
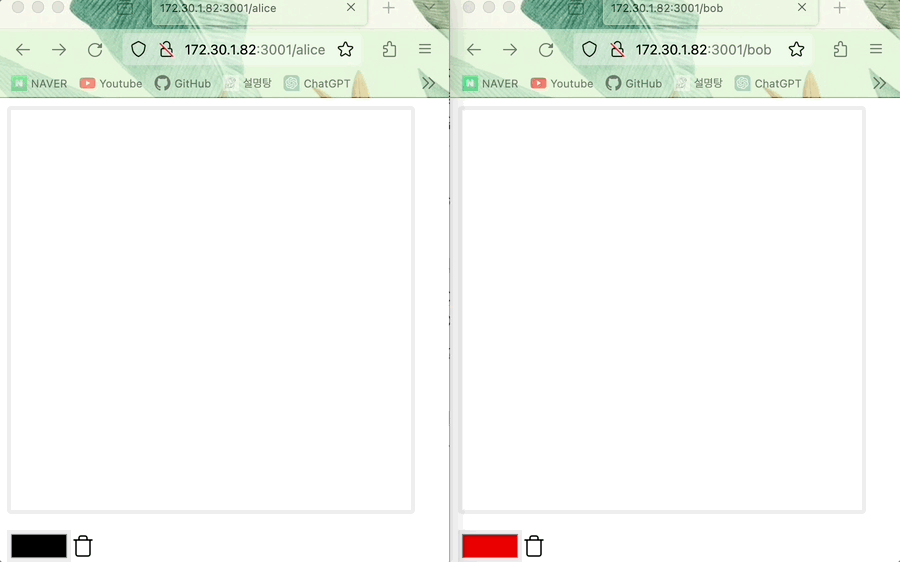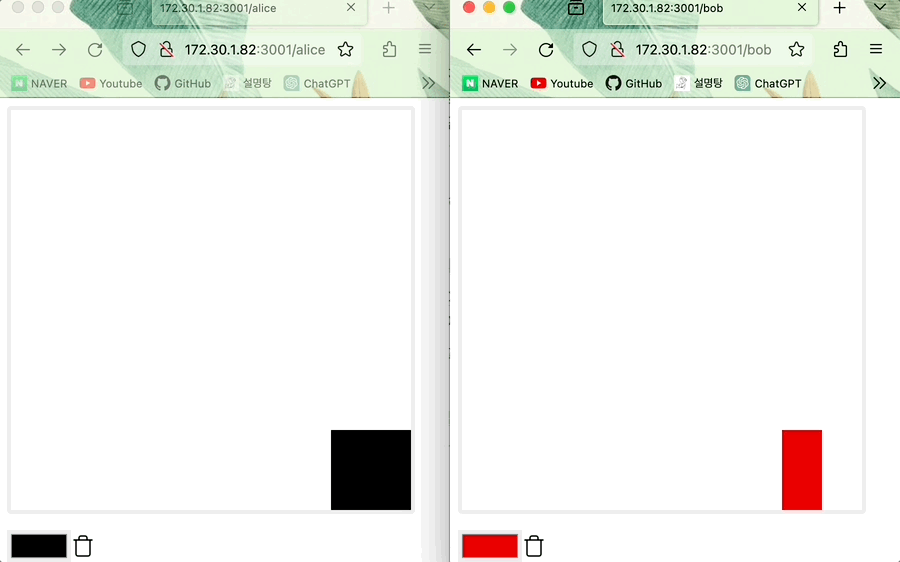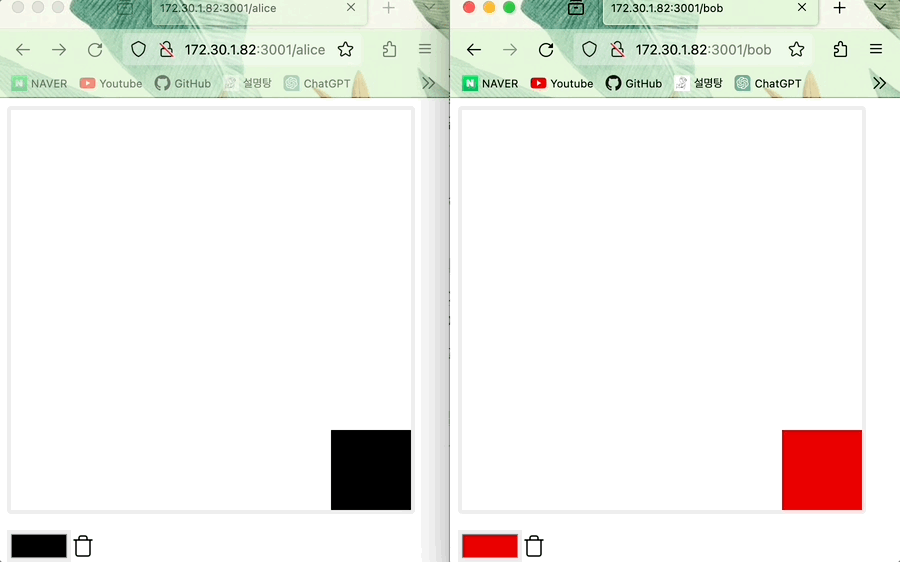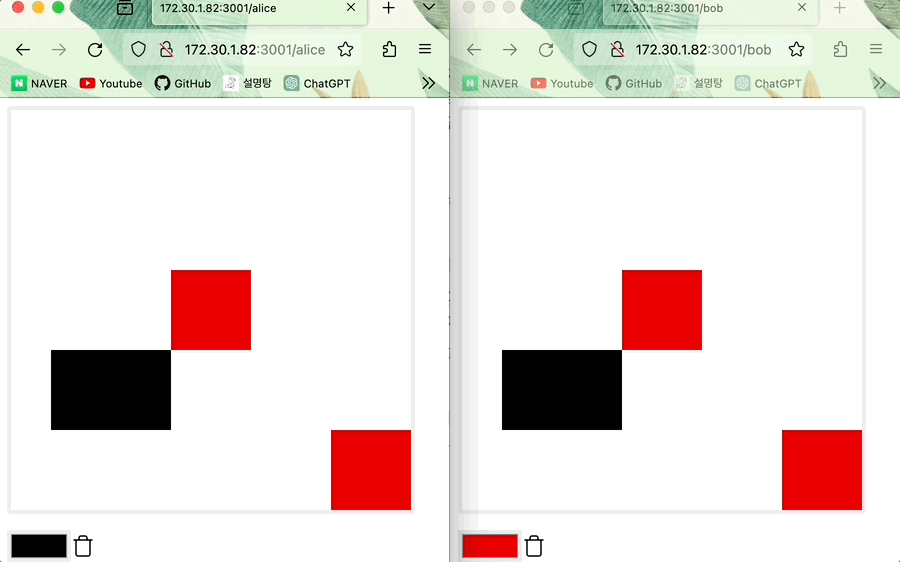
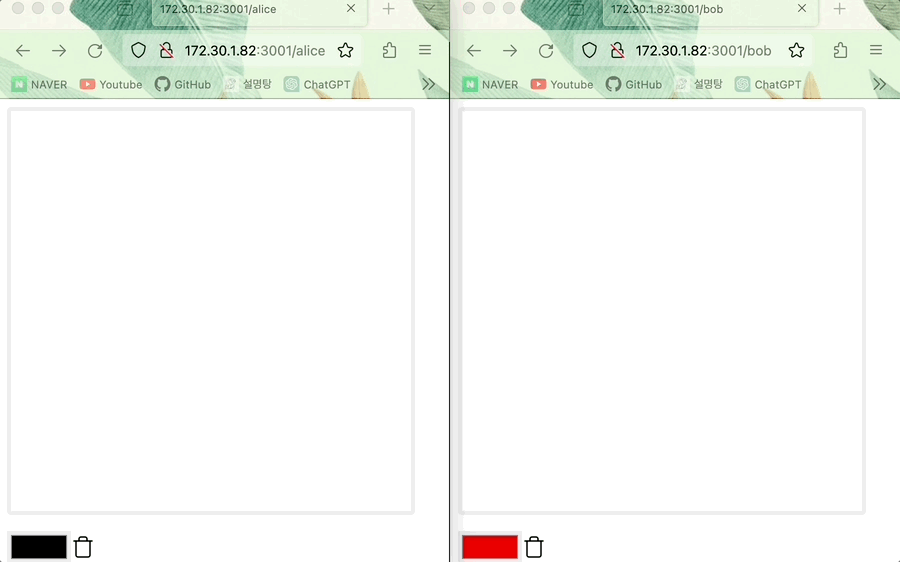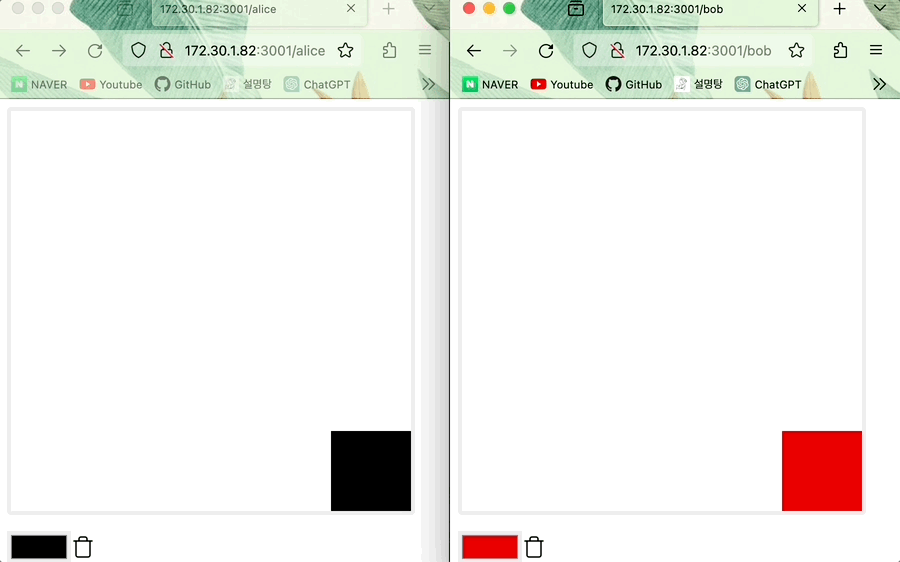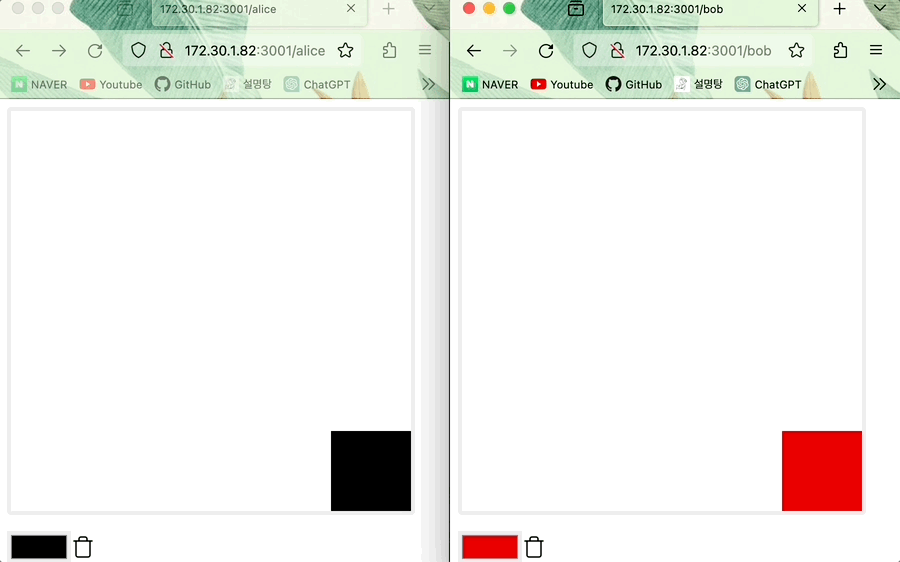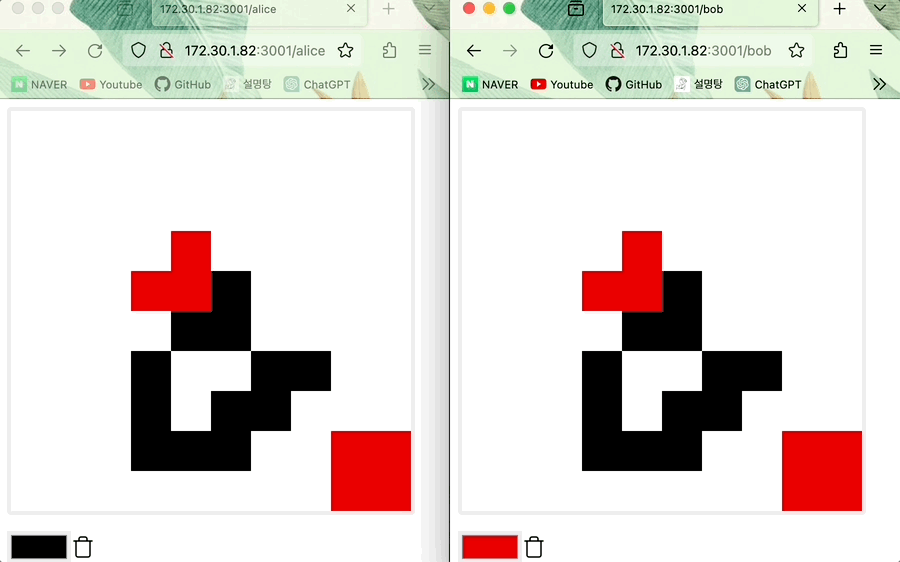
- 동시에 같은 위치에 Alice와 Bob이 그리면 Alice의 그림이 적용된다
- Alice의 그림이 적용된다
실시간 협업 기술로 활용되는 CRDT와 LWW Register에 대해서 알아보았습니다. 생각보다 간단한 로직으로 데이터 일관성을 지킬 수 있는 게 신기한 거 같습니다. 모든 실시간 협업 도구가 CRDT를 사용하는 것은 아니겠지만 CRDT가 사용한 아이디어를 보고 어떻게 실시간으로 여러 사용자가 일관성을 유지한 채 데이터를 공유하는지 엿볼 수 있었습니다. 다음 글에서는 구체적인 코드와 함께 살펴보면서 조금 더 CRDT에 관해 알아보는 시간을 가져보도록 하겠습니다.
참고자료