DB는 어떻게 데이터를 찾는가
2023년 11월 10일학부 시절, ‘파일구조’ 수업을 들었습니다. 파일구조의 마지막 과제로 B+ tree 자료구조를 활용하여 간단한 데이터베이스(이하 DB)를 구현하는 시간이 있었습니다. 호기롭게 과제를 시작했지만, 저의 능력 부족으로 반쪽짜리 과제를 하여 아쉬웠던 기억이 있습니다. 마음 한편 속에 끝내지 못한 DB 과제가 마음에 걸렸었는데, 마침 DB 구현과 관련하여 참고 할 만한 좋은 자료가 있어 이번 기회에 다시 DB 내부 구조를 공부하게 되었습니다. Let's Build a Simple Database 자료를 기반으로 간단하게 DB 구조에 대해 알아보겠습니다.
Let's Build a Simple Database에서 소개하는 DB 구조는 경량 DB로 잘 알려진 SQLite를 참고했습니다. DB와 통신하기 위한 간단한 언어 분석기, VM 그리고 효율적인 데이터 탐색을 위한 B-tree까지 핵심적인 DB 내부 구조를 직접 경험할 수 있습니다.
SQLite 제작자는 SQLite 사용자에게 몇 가지 조언(blessing)을 남기고 저작권을 소유하지 않는 선택을 했습니다. 멋진 말을 남기신 SQLite 개발자 Richard Hipp은 개인적으로 존경하는 개발자입니다.
- May you do good and not evil
- May you find forgiveness for yourself and forgive others
- May you share freely, never taking more than you give
SQLite는 크게 tokenizer, parser, code generator, virtual machine, b-tree, pager, OS interface로 이루어져 있습니다.
- SQLite Architecture
- Tokenizer: query를 토큰화 (tokenize.c)
- Parser: Lemon parser를 통해 토큰 해석 및 parse tree 생성 (parse.y)
- Code Generator: parse tree를 분석 후 bytecode 생성 (ex. select.c, where.c)
- Virtual Machine: 생성한 bytecode를 가지고 b-tree 자료구조에 접근해 select, insert와 같은 동작 실행 (vdbe.c)
- B-tree: 많은 데이터를 효율적으로 조회, 저장을 위한 자료구조 (btree.c)
- Pager: 페이지 단위의 파일 캐시를 위한 추상화 객체 (pager.c)
- OS Interface: SQLite가 여러 운영체제와 호환하기 위한 인터페이스 (ex. os_unix.c, os_win.c)
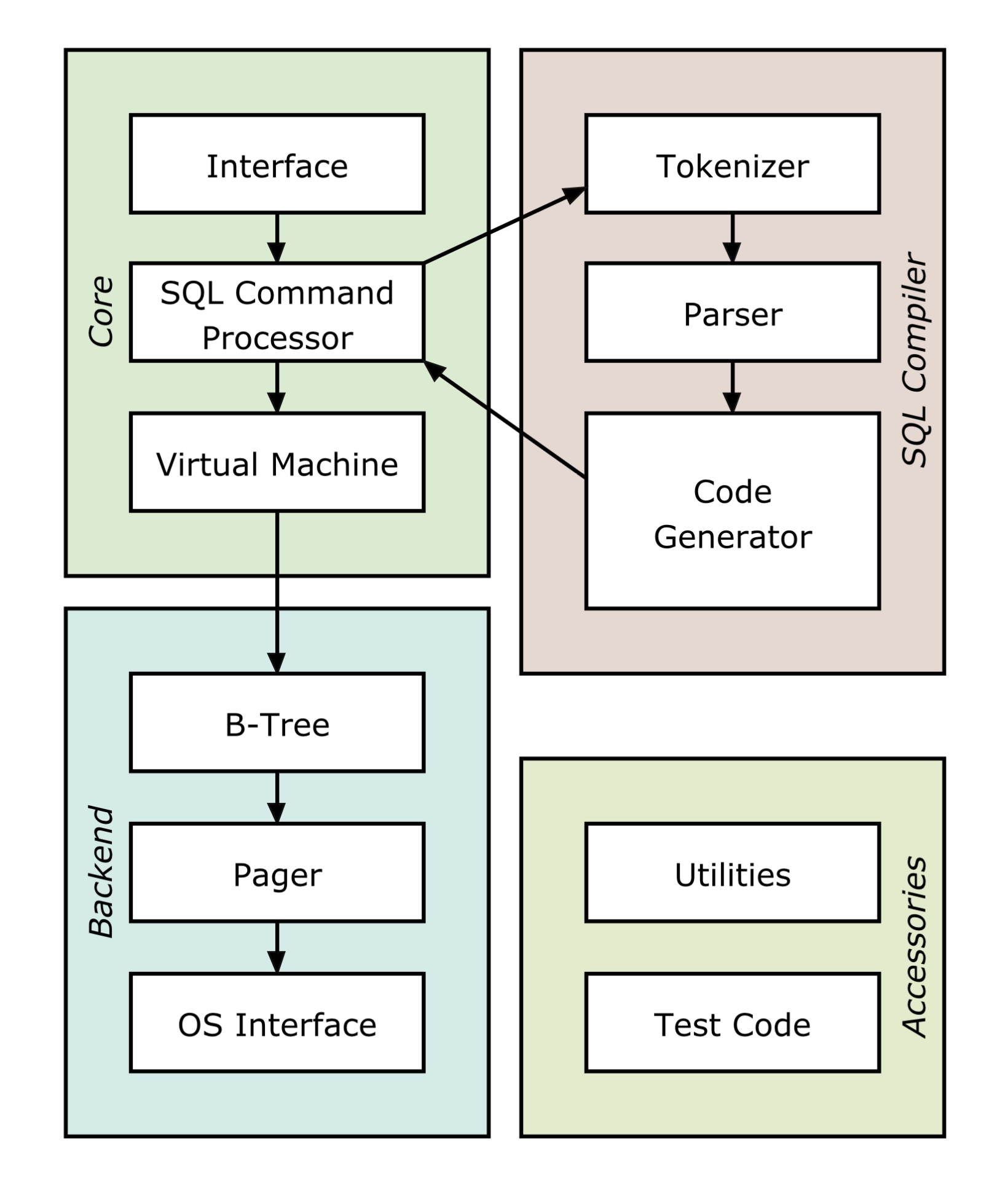
맨 처음 DB 구현을 위해 살펴볼 것은 컴파일러와 VM입니다. 처음부터 어마어마한 주제가 나오지만 괜찮습니다. 저희는 DB 내부 구조에 초점을 둘 것이니 간단하게만 알아봅시다.
SQLite, MySQL, Postgres 등과 같은 DB는 여러 SQL문을 지원하지만 저희가 구현할 DB는 select, insert만 지원합니다. 또한 데이터 형식은 id, username, email로 3개로 제한합니다. 아래는 DB에 데이터를 저장하는 insert 예시입니다.
TEXTinsert 1 seol seol@test.com
사용자가 insert 명령어를 입력한다면 뒤에 오는 데이터 형식이 맞는지 확인(prepare)하고 데이터를 작성(execute)합니다.
CPrepareResult prepareInsert(InputBuffer *inputBuffer, Statement *statement) {
statement->type = STATEMENT_INSERT;
strtok(inputBuffer->buffer, " ");
char *idString = strtok(NULL, " ");
char *username = strtok(NULL, " ");
char *email = strtok(NULL, " ");
if (idString == NULL || username == NULL || email == NULL) {
return PREPARE_SYNTAX_ERROR;
}
int id = atoi(idString);
if (id < 0) {
return PREPARE_NEGATIVE_ID;
}
if (strlen(username) > COLUMN_USERNAME_SIZE) {
return PREPARE_STRING_TOO_LONG;
}
if (strlen(email) > COLUMN_EMAIL_SIZE) {
return PREPARE_STRING_TOO_LONG;
}
statement->rowToInsert.id = id;
strcpy(statement->rowToInsert.username, username);
strcpy(statement->rowToInsert.email, email);
return PREPARE_SUCCESS;
}
ExecuteResult executeInsert(Statement *statement, Table *table) {
...
}
PrepareResult prepareStatement(InputBuffer *inputBuffer, Statement *statement) {
if (strncmp(inputBuffer->buffer, "insert", 6) == 0) {
return prepareInsert(inputBuffer, statement);
}
...
}
ExecuteResult executeStatement(Statement *statement, Table *table) {
switch (statement->type) {
case STATEMENT_INSERT:
return executeInsert(statement, table);
...
}
}
int main(void) {
...
prepareStatement(inputBuffer, &statement);
executeStatement(&statement, table);
...
}
prepareStatement() 함수는 tokenizer, parser의 역할을 하고 executeStatement() 함수는 virtual machine 역할을 합니다.
Parser의 역할을 하는 prepareStatement() 함수는 원래라면 parse tree를 생성하지만 위 예시에서는 statement의 상태를 나타내는 enum(PrepareResult, ExecuteResult) 형식을 반환합니다.
DB는 데이터를 저장할 때 페이지 크기(4KB 배수)로 만들고 번호를 붙여 파일 형태로 저장합니다. 위의 예시로, 데이터를 저장하는데 id(`uint32_t`) 4bytes, username(`char`) 33bytes, email(`char`) 256bytes를 사용하여 293bytes를 사용합니다. 페이지 크기를 4KB로 가정했을 때, 한 페이지 당 13개(4096 / 293 = 13.97)의 데이터를 저장할 수 있습니다. 1~13번 데이터는 페이지 번호 1에 14~26번 데이터는 페이지 번호 2에 저장합니다.

DB 파일 크기를 4KB 단위로 관리하는 이유는 운영체제 가상 메모리의 페이지 크기가 4KB 배수이기 때문입니다. 가상 메모리 한 블록인 페이지 단위에 맞추면 효율적으로 I/O 작업을 할 수 있습니다. 그러면 왜 페이지 크기는 4KB 배수일까요? 🤔
참고로 MySQL의 기본 페이지 크기는 16KB, Postgres는 8KB 입니다.
만약 디스크에 저장된 1번 페이지 파일을 메모리에 올린 상태에서 7번 데이터를 불러온다면 DB는 추가적인 메모리 작업 없이 데이터를 가져올 수 있습니다. 14번 데이터를 불러오고 싶다면 2번 페이지 파일을 메모리에 올려 데이터를 확인합니다.
Cvoid *getPage(Pager *pager, uint32_t pageNum) {
if (pageNum > TABLE_MAX_PAGES) {
printf("Tried to fetch page number out of bounds. %d > %d\n", pageNum, TABLE_MAX_PAGES);
exit(EXIT_FAILURE);
}
/*
Cache miss. Allocate memory and load from file.
*/
if (pager->pages[pageNum] == NULL) {
void *page = malloc(PAGE_SIZE);
uint32_t numPages = pager->fileLength / PAGE_SIZE;
if (pager->fileLength % PAGE_SIZE) {
numPages += 1;
}
/*
Load data to memory by seeking disk.
*/
if (pageNum <= numPages) {
lseek(pager->fileDescriptor, pageNum * PAGE_SIZE, SEEK_SET);
ssize_t bytesRead = read(pager->fileDescriptor, page, PAGE_SIZE);
if (bytesRead == -1) {
printf("Error reading file: %d\n", errno);
exit(EXIT_FAILURE);
}
}
pager->pages[pageNum] = page;
if (pageNum >= pager->numPages) {
pager->numPages = pageNum + 1;
}
}
return pager->pages[pageNum];
}
Pager는 디스크에 저장된 DB 파일에 대한 I/O 작업을 담당합니다. 페이지 단위로 데이터를 관리하고 디스크에서 메모리로 데이터를 올려야 할지의 캐싱 여부를 판단하면서 DB 효율을 증가시키는 역할을 합니다.
메모리에 데이터를 올리는 것도 중요하지만 연산 속도, 메모리 사용에 영향을 끼치는 데이터를 관리하는 자료구조 또한 중요합니다. 데이터를 쉽고 간단하게 저장하고 조회할 수 있는 구조는 배열입니다. 데이터를 어떻게 정렬하는가에 따라 배열의 성능이 달라집니다.
데이터가 정렬되지 않는 배열에서 특정 값을 찾고 싶다면 배열 처음부터 끝까지 탐색해야 합니다(O(n)). 데이터가 정렬된 배열이라면 배열 중간부터 시작해서 탐색하면 됩니다(O(log(n))). 데이터가 정렬된 배열이 데이터가 정렬되지 않는 배열보다 조회를 빠르게 할 수 있는 장점이 있지만, 데이터 저장은 끝에 데이터를 두기만 하면 되는 데이터가 정렬되지 않는 배열(O(1))이 전체적으로 배열 순서를 변경해야 하는 데이터가 정렬된 배열(O(n))보다 유리합니다.
| 데이터가 정렬되지 않는 배열 | 데이터가 정렬된 배열 | B-tree | |
|---|---|---|---|
| 저장 | O(1) | O(n) | O(log(n)) |
| 삭제 | O(n) | O(n) | O(log(n)) |
| 조회 | O(n) | O(log(n)) | O(log(n)) |
보다 효율적인 데이터 조회와 저장을 위해 DB는 배열 대신 트리 구조 중 한 종류인 B-tree(b tree not b minus tree)를 사용합니다. B-tree는 internal node, leaf node 개념을 가지고 앞선 배열보다 효율적으로 데이터를 다루어 저장, 조회에 O(log(n)) 성능을 보여줍니다.
SQLite는 index를 저장할 때는 b-tree 구조를 사용하고, table를 저장할 때는 b+ tree를 사용합니다.
Internal node는 internal node 위치를 알려줄 key와 자식 위치를 가리키는 포인터 값을 가지며, leaf node는 key와 사용자가 입력한 id, username, email와 같은 실질적인 데이터를 가집니다. B-tree의 핵심은 어느 node의 데이터가 넘치지 않도록 balanced하게 데이터를 저장합니다.
| Order-m tree | Internal Node | Leaf Node |
|---|---|---|
| 무엇을 저장하는가 | key와 children 포인터 | key와 데이터(ex. id, email) |
| key의 개수 | 최대 (m-1)개 | 들어갈 수 있는 만큼 |
| 포인터 개수 | (key+ 1)개 | 없음 |
| 데이터(value)의 개수 | 없음 | key 개수 |
| key가 쓰이는 용도 | 데이터 검색을 위한 경로 탐색(leaf node의 최대값) | 데이터 식별 및 검색 |
order-m tree는 다음과 같은 의미를 같습니다.
- internal node 당 m개 까지 children을 가질 수 있다
- internal node 당 최소 (m-1)개의 children을 가진다
- internal node 당 (m-1)개까지 key를 가질 수 있다
- internal node 당 최소 (m-2)개의 key를 가진다
다음은 B-tree of order 3의 데이터 저장 예시입니다.
- node 초기화 (첫 node는 leaf node이자 root node)
- (5, 12 저장) 데이터가 들어오면 정렬되게 저장(아래의 예제에서는 id 값을 기준으로 정렬)
- (1 저장) leaf node에 데이터가 3개 이상 저장되면 internal node 1개, leaf node 2개로 분리 후 저장
- (2 저장) internal node의 key를 기준으로 정렬되게 저장
- (18, 21 저장) internal node에 데이터가 3개가 들어오면 internal node 3개로 분리 후 저장
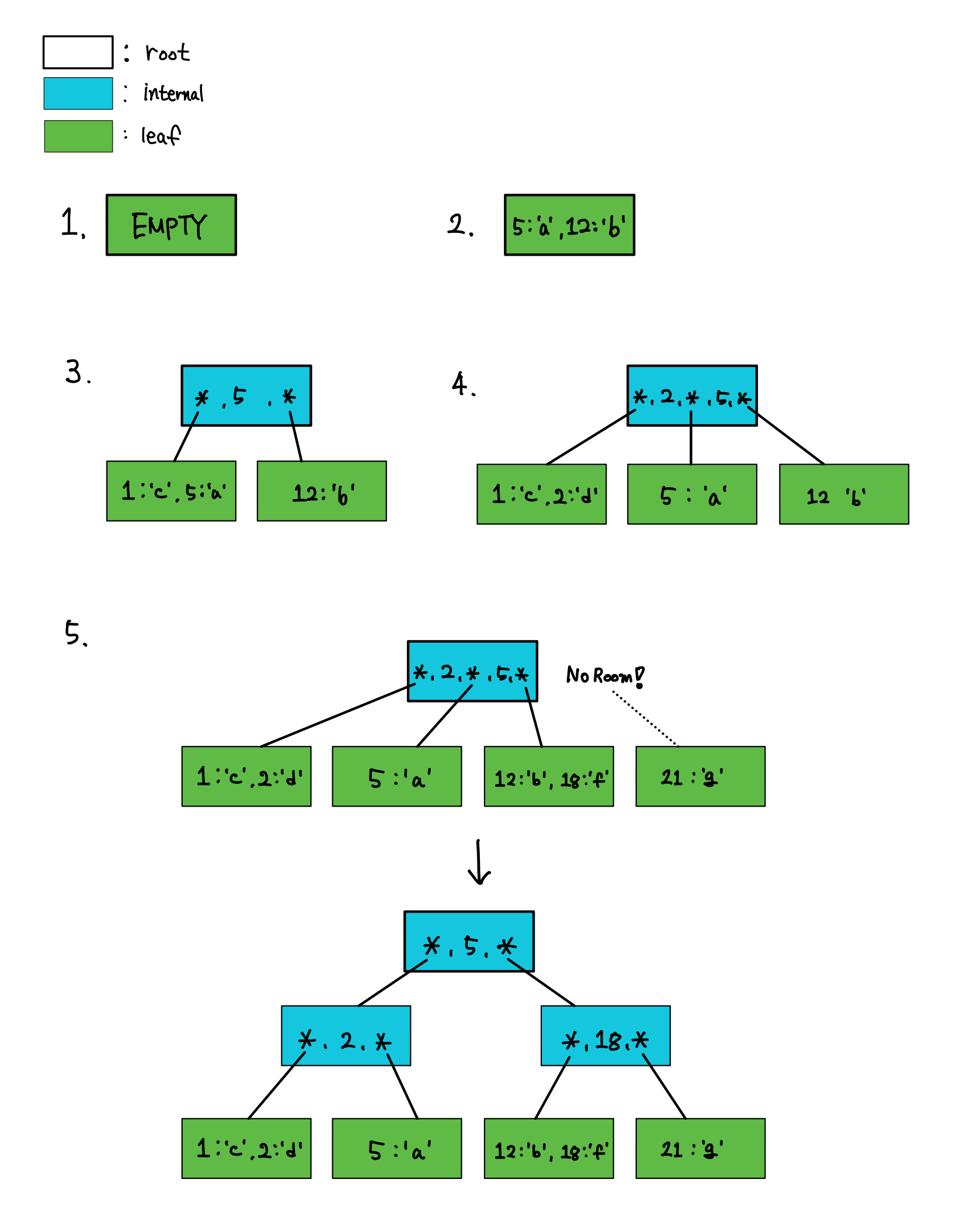
3번과 5번이 B-tree에서의 핵심 알고리즘입니다. 3번과 같이 leaf node가 넘쳤을 때 internal node 1개를 만들고, leaf node 2개로 나누는 두 가지의 알고리즘이 필요합니다. SQLite는 leaf node 2개로 나누는 작업을 다음과 같이 설명합니다.
If there is no space on the leaf node, we would split the existing entries residing there and the new one (being inserted) into two equal halves: lower and upper halves. (Keys on the upper half are strictly greater than those on the lower half) We allocate a new leaf node, and move the upper half into the new node. - SQLite Database System: Design and Implementation
Leaf node에 데이터가 꽉 차게 되면 leaf node 2개, internal node 1개로 분리되는데 그 과정을 차례로 보면 다음과 같습니다.
- Leaf node 분리
- 새로운 leaf node 생성
- 새로운 leaf node에 기존 leaf node 정보 저장
- 데이터를 반으로 잘라 상위 key(key 크기가 큰)는 새로운 leaf node에, 나머지는 기존 leaf node에 저장
- Internal node 생성
- 새로운 internal node에 기존 leaf node 데이터를 복사하여 생성
- internal node 초기화
- child(left node) node 포인터 및 key 저장
- right node child 포인터 저장
설명만 들으면 이해하기 어렵지만 위 그림의 과정을 보면서 감을 잡는 것만으로도 충분하다고 생각합니다.
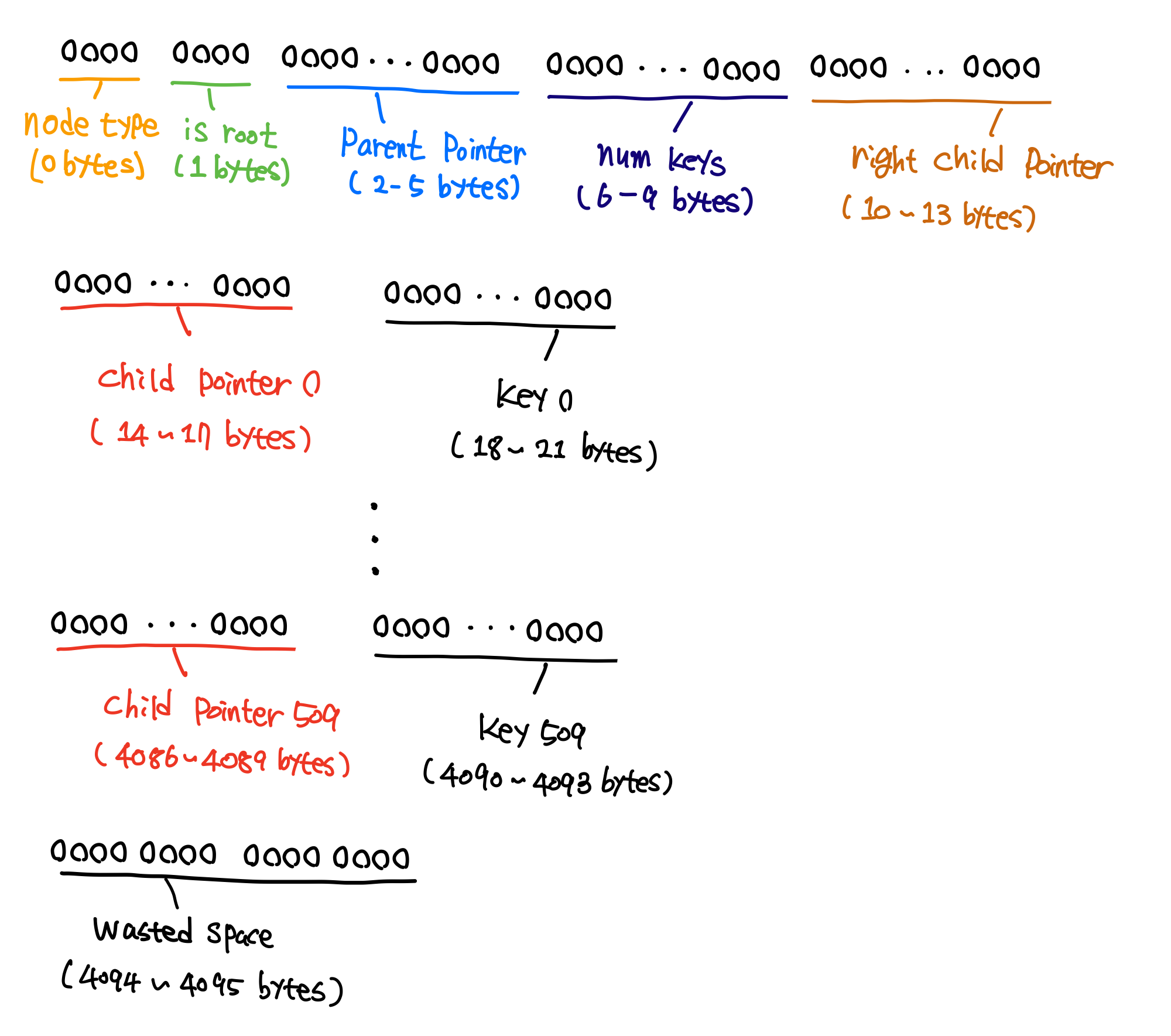
Leaf node의 구조와 internal node는 다음과 같이 구성되어있습니다.
- Leaf node 구조
node_type: 해당 노드가 leaf node인지 internal node인지 구별is_root: 해당 노드가 root 노드인지 구별parent_pointer: 부모 노드 포인터 표시num_cells: 해당 노드에 몇 개의 데이터가 있는지 알려주는 용도key: 몇 번째의 데이터를 식별해주는 용도value: 사용자가 입력한 데이터를 저장하는 용도

- Internal node 구조
node_type: 해당 노드가 leaf node인지 internal node인지 구별is_root: 해당 노드가 root 노드인지 구별parent_pointer: 부모 노드 포인터 표시num_cells: 해당 노드에 몇 개의 데이터가 있는지 알려주는 용도right_child_pointer: 맨 오른쪽 노드 포인터 표시child_pointer: 나머지 child 포인터 표시(맨 왼쪽 부터)key: 해당 child 노드의 최대값
Cvoid leafNodeSplitAndInsert(Cursor *cursor, uint32_t key, Row *value) {
void *oldNode = getPage(cursor->table->pager, cursor->pageNum);
uint32_t oldMax = getNodeMaxKey(cursor->table->pager, oldNode);
uint32_t newPageNum = getUnusedPageNum(cursor->table->pager);
void *newNode = getPage(cursor->table->pager, newPageNum);
initializeLeafNode(newNode);
*nodeParent(newNode) = *nodeParent(oldNode);
*leafNodeNextLeaf(newNode) = *leafNodeNextLeaf(oldNode);
*leafNodeNextLeaf(oldNode) = newPageNum;
/*
LEAF_NODE_MAX_CELLS: 한 페이지에 최대로 데이터를 저장할 수 있는 수
ex. 4096(한 페이지 크기) / 297(사용자 데이터 크기) = 13
*/
for (int32_t i = LEAF_NODE_MAX_CELLS; i >= 0; i--) {
void *destinationNode;
/*
데이터를 왼쪽 노드(oldNode)에 저장할지 오른쪽 노드(newNode)에 저장할지 결정
*/
if (i >= LEAF_NODE_LEFT_SPLIT_COUNT) {
destinationNode = newNode;
} else {
destinationNode = oldNode;
}
uint32_t indexWithinNode = i % LEAF_NODE_LEFT_SPLIT_COUNT;
void *destination = leafNodeCell(destinationNode, indexWithinNode);
if (i == cursor->cellNum) {
/*
leaf node에 사용자 입력 저장
*/
} else if (i > cursor->cellNum) {
/*
왼쪽 노드(oldNode)의 (i - 1)번째 데이터를 destination의 셀 위치에 저장
*/
} else {
/*
왼쪽 노드(oldNode)의 i번째 데이터를 destination의 셀 위치에 저장
*/
}
}
...
if (isNodeRoot(oldNode)) {
/*
새로운 internal node(=root node) 만들기
*/
} else {
/*
기존에 있는 internal node 정보 업데이트
*/
}
}
Internal node에 데이터가 꽉 차게 되면 internal node 3개로 분리되는데 전제적인 과정은 앞서 살펴본 leaf node 분리와 유사합니다.
Cvoid internalNodeSplitAndInsert(Table *table, uint32_t parentPageNum, uint32_t childPageNum) {
uint32_t oldPageNum = parentPageNum;
void *oldNode = getPage(table->pager, oldPageNum);
uint32_t oldMax = getNodeMaxKey(table->pager, oldNode);
void *child = getPage(table->pager, childPageNum);
uint32_t childMax = getNodeMaxKey(table->pager, child);
uint32_t newPageNum = getUnusedPageNum(table->pager);
/*
포인터를 업데이트하기 전에 이 작업에 root 분할이 포함되는지 여부를 기록하는 플래그를 선언하면,
테이블의 새 root가 생성되는 단계에서 새로 생성된 노드를 삽입합니다.
그렇지 않은 경우, 이전 노드의 키가 전송된 후에 새로 생성된 노드를 부모 노드에 삽입해야 합니다.
새로 생성된 노드의 parent가 새로 초기화된 루트 노드가 아닌 경우 이 작업을 수행할 수 없는데,
이 경우 parent에 분할 중인 기존 노드 외에 기존 키가 있을 수 있기 때문입니다.
이 경우 parent에서 새로 생성된 노드를 배치할 위치를 찾아야 하는데,
다음과 같은 경우 아직 키가 없는 경우 올바른 인덱스에 삽입할 수 없습니다.
*/
uint32_t splittingRoot = isNodeRoot(oldNode);
void *parent;
void *newNode;
/*
root를 분할하는 경우 새 root의 왼쪽 child을 가리키도록 oldNode를 업데이트해야 하며,
newPageNum은 이미 새 root의 오른쪽 child을 가리키게 됩니다.
*/
if (splittingRoot) {
createNewRoot(table, newPageNum);
parent = getPage(table->pager, table->rootPageNum);
oldPageNum = *internalNodeChild(parent, 0);
oldNode = getPage(table->pager, oldPageNum);
} else {
parent = getPage(table->pager, *nodeParent(oldNode));
newNode = getPage(table->pager, newPageNum);
initializeInternalNode(newNode);
}
uint32_t *oldNumKeys = internalNodeNumKeys(oldNode);
uint32_t curPageNum = *internalNodeRightChild(oldNode);
void *cur = getPage(table->pager, curPageNum);
/*
먼저 오른쪽 child을 새 노드에 넣고 이전 노드의 오른쪽 child을 유효하지 않은 페이지 번호로 설정합니다.
*/
internalNodeInsert(table, newPageNum, curPageNum);
*nodeParent(cur) = newPageNum;
*internalNodeRightChild(oldNode) = INVALID_PAGE_NUM;
/*
가운데 키에 도달할 때까지 각 키에 대해 키와 child을 새 노드로 이동합니다.
*/
for (int i = INTERNAL_NODE_MAX_CELLS - 1; i > INTERNAL_NODE_MAX_CELLS / 2;
i--) {
curPageNum = *internalNodeChild(oldNode, i);
cur = getPage(table->pager, curPageNum);
internalNodeInsert(table, newPageNum, curPageNum);
*nodeParent(cur) = newPageNum;
(*oldNumKeys)--;
}
/*
현재 가장 높은 키인 가운데 키 앞의 자식을 child의 오른쪽 자식으로 설정합니다, 키 수를 줄입니다.
*/
*internalNodeRightChild(oldNode) = *internalNodeChild(oldNode, *oldNumKeys - 1);
(*oldNumKeys)--;
/*
분할 후 두 노드 중 어느 노드에 삽입할 child을 포함할지 결정합니다, child을 삽입합니다.
*/
uint32_t maxAfterSplit = getNodeMaxKey(table->pager, oldNode);
uint32_t destinationPageNum = childMax < maxAfterSplit ? oldPageNum : newPageNum;
internalNodeInsert(table, destinationPageNum, childPageNum);
*nodeParent(child) = destinationPageNum;
updateInternalNodeKey(parent, oldMax, getNodeMaxKey(table->pager, oldNode));
if (!splittingRoot) {
internalNodeInsert(table, *nodeParent(oldNode), newPageNum);
*nodeParent(newNode) = *nodeParent(oldNode);
}
}
B-tree 알고리즘을 이론으로만 보면 엄청나게 복잡하지는 않아 보이는데, 코드로 보면 여러 케이스를 고려해야 하다 보니 다소 복잡합니다. 제 경험상 split이 일어나기 직전과 직후의 DB 파일을 hex editor로 비교하면서 보는 게 이해하기가 수월했던 거 같습니다. 지금 봐도 복잡하고 어려운데 이런 알고리즘을 학부 과제로 내주었다니… 이번 기회를 통해 DB 데이터가 어떻게 저장이 되고 B-tree 알고리즘이 동작하는지 한층 더 이해하게 되었습니다. 물론 real world에서 사용하고 있는 DB는 더 효율적이고 최적화가 되어있겠지만 기본적인 DB가 동작하는 방식을 볼 수 있어서 즐거웠습니다.
자세한 코드 구현 과정을 보고 싶다면 Let's Build a Simple Database의 GitHub나 모듈별로 나눠서 정리한 저의 GitHub를 참고하면 좋을 거 같습니다.